
Machine Learning Up to Date #29
Here's ML UTD #29 from the LifeWithData blog! We help you separate the signal from the noise in today's hectic front lines of software engineering and machine learning.
LifeWithData strives to deliver curated machine learning & software engineering updates that point the reader to key developments without superfluous details. This enables frequent, concise updates across the industry without information overload.
Application
- Applying the MLOps Lifecycle
- NeurIPS 2020 Papers: Takeaways for a Deep Learning Engineer
- Mobile Machine Learning: 2020 Year in Review
Theory
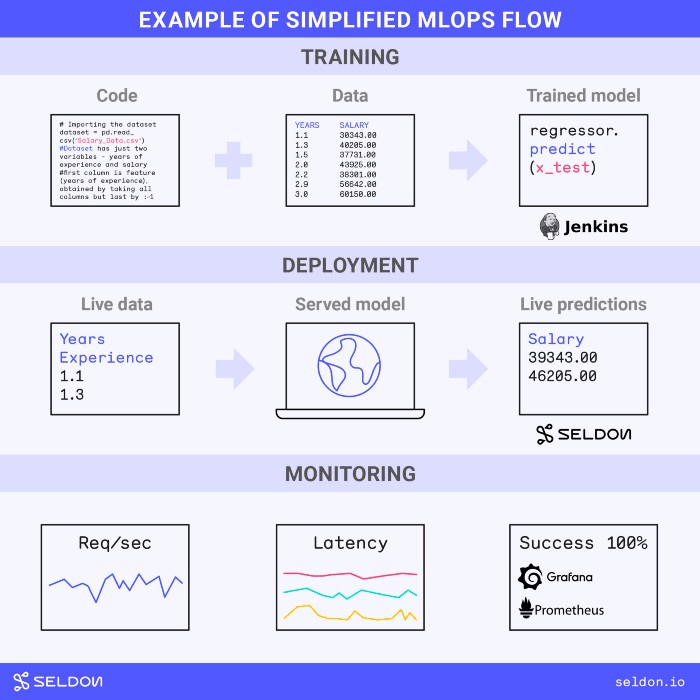
Applying the MLOps Lifecycle ☝
MLOps can be difficult for teams to get a grasp of. It is a new field and most teams tasked with MLOps projects are currently coming at it from a different background. It is tempting to copy an approach from another project. But the needs of MLOps projects can vary greatly. What is needed is to understand the specific needs of each MLOps project. This requires understanding the types of MLOps needs and how they arise.
... keep reading
The Rundown
NeurIPS 2020 Papers: Takeaways for a Deep Learning Engineer ☝
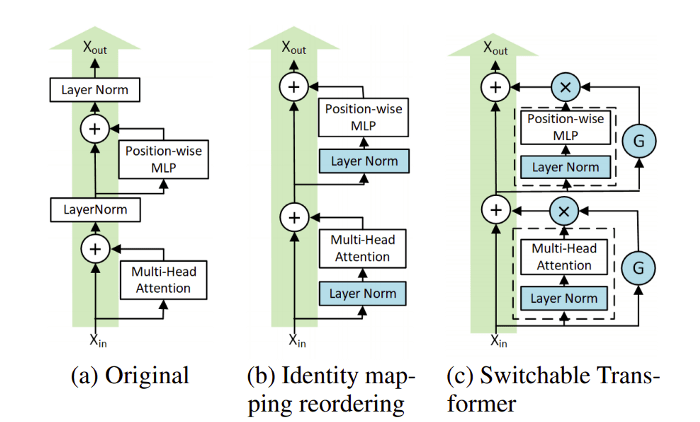
Advances in Deep Learning research are of great utility for a Deep Learning engineer working on real-world problems as most of the Deep Learning research is empirical with validation of new techniques and theories done on datasets that closely resemble real-world datasets/tasks (ImageNet pre-trained weights are still useful!). But, churning a vast amount of research to acquire techniques, insights, and perspectives that are relevant to a DL engineer is time-consuming, stressful, and not the least overwhelming. \[..\] Therefore, I went through all the titles of NeurIPS 2020 papers (more than 1900!) and read abstracts of 175 papers, and extracted DL engineer relevant insights from the following papers
... keep reading
The Rundown
Mobile Machine Learning: 2020 Year in Review ☝

It goes without saying that 2020 was a trying, difficult yeah, on multiple levels. The crumpled 2020 in the cover image felt immediately recognizable and fitting. But in the midst of it all, from our little corner of the universe at [Fritz AI](http://fritz.ai/), it’s been heartening and inspiring to see the mobile machine learning world grow and evolve in new and exciting ways. We saw tons of direct investment in on-device machine learning, significant strides forward in both hardware and software, and we even encountered a new player in the mobile ML game. To leave 2020 on a high note, we wanted to summarize some of the most exciting and interesting developments in mobile machine learning. See you all in 2021!
... keep reading
The Rundown
Using JAX to accelerate [Deepmind] research ☝

DeepMind engineers accelerate our research by building tools, scaling up algorithms, and creating challenging virtual and physical worlds for training and testing artificial intelligence (AI) systems. As part of this work, we constantly evaluate new machine learning libraries and frameworks. Recently, we've found that an increasing number of projects are well served by JAX, a machine learning framework developed by Google Research teams. JAX resonates well with our engineering philosophy and has been widely adopted by our research community over the last year. Here we share our experience of working with JAX, outline why we find it useful for our AI research, and give an overview of the ecosystem we are building to support researchers everywhere.
... keep reading
The Rundown
Wav2vec 2.0: Learning the structure of speech from raw audio ☝

There are thousands of languages spoken around the world, many with several different dialects, which presents a huge challenge for building high-quality speech recognition technology. It’s simply not feasible to obtain resources for each dialect and every language across the many possible domains (read speech, telephone speech, etc.). Our new model, wav2vec 2.0, uses self-supervision to push the boundaries by learning from unlabeled training data to enable speech recognition systems for many more languages, dialects, and domains. With just one hour of labeled training data, wav2vec 2.0 outperforms the previous state of the art on the 100-hour subset of the LibriSpeech benchmark — using 100 times less labeled data. Similar to the Bidirectional Encoder Representations from Transformers (BERT), our model is trained by predicting speech units for masked parts of the audio. A major difference is that speech audio is a continuous signal that captures many aspects of the recording with no clear segmentation into words or other units. Wav2vec 2.0 tackles this issue by learning basic units that are 25ms long to enable learning of high-level contextualized representations. These units are then used to describe many different speech audio recordings and make wav2vec more robust. This enables us to build speech recognition systems that can outperform the best semisupervised methods, even with 100x less labeled training data. Wav2vec 2.0 is part of our vision for machine learning models that rely less on labeled data, thanks to self-supervised learning. Self-supervision has helped us advance image classification, video understanding, and our content understanding systems. We hope that the algorithm will enable improved speech technology for many more languages, dialects, and domains, and lead to improvements for existing systems.
... keep reading
The Rundown
Neuroscientists find a way to make object-recognition models perform better ☝

Computer vision models known as convolutional neural networks can be trained to recognize objects nearly as accurately as humans do. However, these models have one significant flaw: Very small changes to an image, which would be nearly imperceptible to a human viewer, can trick them into making egregious errors such as classifying a cat as a tree. A team of neuroscientists from MIT, Harvard University, and IBM have developed a way to alleviate this vulnerability, by adding to these models a new layer that is designed to mimic the earliest stage of the brain’s visual processing system. In a new study, they showed that this layer greatly improved the models’ robustness against this type of mistake. “Just by making the models more similar to the brain’s primary visual cortex, in this single stage of processing, we see quite significant improvements in robustness across many different types of perturbations and corruptions,” says Tiago Marques, an MIT postdoc and one of the lead authors of the study.
... keep reading
The Rundown