
Machine Learning Up to Date #21

Here's ML UTD #21 from the LifeWithData blog! We help you separate the signal from the noise in today's hectic front lines of software engineering and machine learning.
LifeWithData strives to deliver curated machine learning & software engineering updates that point the reader to key developments without superfluous details. This enables frequent, concise updates across the industry without information overload.
Application
- Resilience and Vibrancy: The 2020 Data & AI Landscape
- Feature Store: The Missing Data Layer in ML Pipelines?
- Using a TensorFlow Deep Learning Model for Forex Trading
Theory
Resilience and Vibrancy: The 2020 Data & AI Landscape ☝
In a year like no other in recent memory, the data ecosystem is showing not just remarkable resilience but exciting vibrancy. When COVID hit the world a few months ago, an extended period of gloom seemed all but inevitable. Yet, as per Satya Nadella, “_two years of digital transformation \[occurred\] in two months_”. Cloud and data technologies (data infrastructure, machine learning / artificial intelligence, data driven applications) are at the heart of digital transformation. As a result, many companies in the data ecosystem have not just survived, but in fact thrived, in an otherwise overall challenging political and economic context.
... keep reading
The Rundown
Feature Store: The Missing Data Layer in ML Pipelines? ☝

A feature store is a central vault for storing documented, curated, and access-controlled features. In this blog post, we discuss the state-of-the-art in data management for deep learning and present the first open-source feature store, available in Hopsworks.
... keep reading
Using a TensorFlow Deep Learning Model for Forex Trading ☝

I have previously created a model to predict the Forex market [...] Now we want to use this model for trading under a commercial trading platform and see if it is going to generate a profit. The techniques used in this story are focusing on the model in my previous story, but they can be tweaked to fit another model. The intention here is to make the model usable by other systems, e.g. a trading platform.
... keep reading
The Rundown
Fast reinforcement learning through the composition of behaviours ☝

A major limitation in RL is that current methods require vast amounts of training experience. For example, in order to learn how to play a single Atari game, an RL agent typically consumes an amount of data corresponding to several weeks of uninterrupted playing. A [study](http://gershmanlab.webfactional.com/pubs/Tsividis17.pdf) led by researchers at MIT and Harvard indicated that in some cases, humans are able to reach the same performance level in just fifteen minutes of play. One possible reason for this discrepancy is that, unlike humans, RL agents usually learn a new task from scratch. We would like our agents to leverage knowledge acquired in previous tasks to learn a new task more quickly, in the same way that a cook will have an easier time learning a new recipe than someone who has never prepared a dish before. In [an article](https://www.pnas.org/content/early/2020/08/13/1907370117) recently published in the Proceedings of the National Academy of Sciences (PNAS), we describe a framework aimed at endowing our RL agents with this ability.
... keep reading
The Rundown
LSTMs Compose (and Learn) Bottom-Up ☝
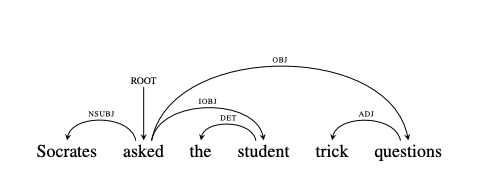
Recent work in NLP shows that LSTM language models capture hierarchical structure in language data. In contrast to existing work, we consider the learning process that leads to their compositional behavior. For a closer look at how an LSTM's sequential representations are composed hierarchically, we present a related measure of Decompositional Interdependence (DI) between word meanings in an LSTM, based on their gate interactions. We connect this measure to syntax with experiments on English language data, where DI is higher on pairs of words with lower syntactic distance. To explore the inductive biases that cause these compositional representations to arise during training, we conduct simple experiments on synthetic data. These synthetic experiments support a specific hypothesis about how hierarchical structures are discovered over the course of training: that LSTM constituent representations are learned bottom-up, relying on effective representations of their shorter children, rather than learning the longer-range relations independently from children.
... keep reading
The Rundown
Fourier Neural Operator for Parametric Partial Differential Equations ☝
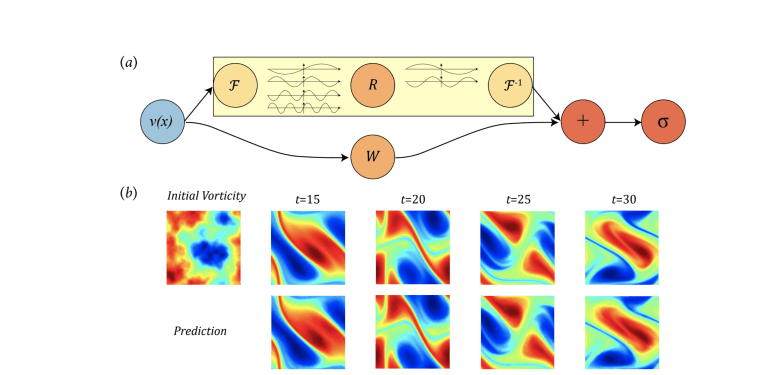
The classical development of neural networks has primarily focused on learning mappings between finite-dimensional Euclidean spaces. Recently, this has been generalized to neural operators that learn mappings between function spaces. For partial differential equations (PDEs), neural operators directly learn the mapping from any functional parametric dependence to the solution. Thus, they learn an entire family of PDEs, in contrast to classical methods which solve one instance of the equation. In this work, we formulate a new neural operator by parameterizing the integral kernel directly in Fourier space, allowing for an expressive and efficient architecture. We perform experiments on Burgers' equation, Darcy flow, and the Navier-Stokes equation (including the turbulent regime). Our Fourier neural operator shows state-of-the-art performance compared to existing neural network methodologies and it is up to three orders of magnitude faster compared to traditional PDE solvers.
... keep reading
The Rundown