
Machine Learning Up to Date #43

Here's ML UTD #43 from the LifeWithData blog! We help you separate the signal from the noise in today's hectic front lines of software engineering and machine learning.
LifeWithData strives to deliver curated machine learning & software engineering updates that point the reader to key developments without superfluous details. This enables frequent, concise updates across the industry without information overload.
Application
- The Next Evolution of Data Catalogs: Data Discovery Platforms
- Machine Learning in production: the Booking.com approach
- The Netflix Cosmos Platform
Theory
The Next Evolution of Data Catalogs: Data Discovery Platforms ☝
As someone who has spent 13 years in the weeds of data, I witnessed the rise of the “data-driven” trend first hand. Before starting and selling my first data startup, I spent time as a statistical analyst building sales forecasting models in R, a software engineer creating data transformation jobs, and a product manager running A/B tests and analyzing user behaviors. What all these roles had in common was that they gave me an understanding that the context of data — ****what it represents, how it was generated, when it was updated last, and the ways it could be joined with other datasets — is essential to maximizing the data’s potential and driving successful outcomes. However, accessing and understanding the context of data is quite difficult. This is because the context of data is often tribal knowledge, meaning it lives only in the brains of the engineers or analysts who have worked with it recently. When other data consumers need to understand the context of data, the shortest path is to find someone who has used the data before and learn it from them. That becomes a real problem as organizations scale. Finding the right person with the correct context takes time, and you might need to talk to multiple people in order to gather a full understanding of your data. [... keep reading](https://blog.selectstar.com/the-evolution-of-data-catalogs-the-data-discovery-platform-1627772ca760?gi=495737f9d1bd)
... keep reading
The Rundown
Machine Learning in production: the Booking.com approach ☝
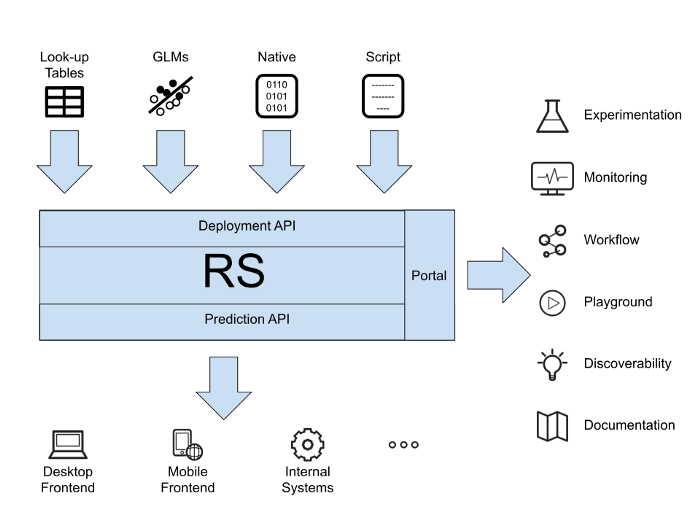
During the last five years, Machine Learning became a standard tool for Product Development in Booking.com. Today, it plays a role in every step of the customer journey. Hundreds of Data Scientists build, deploy and experiment with hundreds of machine-learned models exposing them to millions of users every day. Supporting Machine Learning at scale involves many challenges, not least of which is shipping the models to production reliably, as fast as possible and accommodating a large variety of model types, invocation settings, libraries, data sources, monitoring approaches, etc. Inspired by one of the core values of Booking.com (*diversity gives us strength*), we built a system that supports a large variety of Machine Learning approaches. In this article we present RS, our Machine Learning *Productionization* System. [... keep reading](https://booking.ai/https-booking-ai-machine-learning-production-3ee8fe943c70)
... keep reading
The Rundown
The Netflix Cosmos Platform ☝
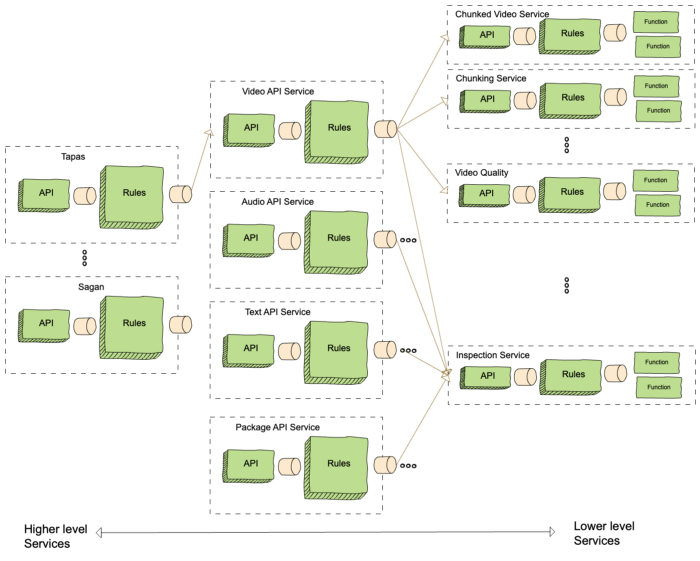
Cosmos is a computing platform that combines the best aspects of microservices with asynchronous workflows and serverless functions. Its sweet spot is applications that involve resource-intensive algorithms coordinated via complex, hierarchical workflows that last anywhere from minutes to years. It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. This article will explain why we built Cosmos, how it works and share some of the things we have learned along the way. [... keep reading](https://netflixtechblog.com/the-netflix-cosmos-platform-35c14d9351ad)
... keep reading
The Rundown
Deep Learning for Phenotype Compound Screening ☝
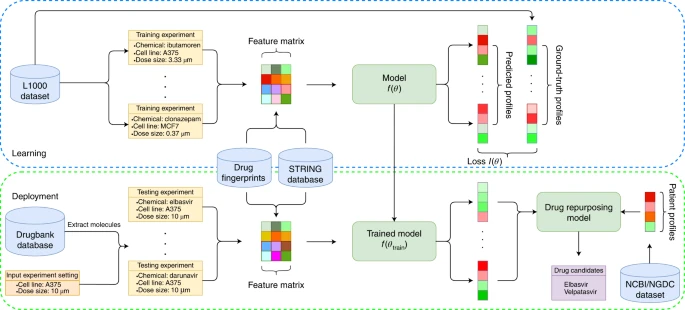
Phenotype-based compound screening has advantages over target-based drug discovery, but is unscalable and lacks understanding of mechanism of drug action. A chemical-induced gene expression profile provides a mechanistic signature of phenotypic response; however, the use of such data is limited by their sparseness, unreliability and relatively low throughput. Few methods can perform phenotype-based de novo chemical compound screening. Here we propose a mechanism-driven neural network-based method, DeepCE—which utilizes a graph neural network and multihead attention mechanism to model chemical substructure–gene and gene–gene associations—for predicting the differential gene expression profile perturbed by de novo chemicals. Moreover, we propose a novel data augmentation method that extracts useful information from unreliable experiments in the L1000 dataset. The experimental results show that DeepCE achieves superior performances to state-of-the-art methods. The effectiveness of gene expression profiles generated from DeepCE is further supported by comparing them with observed data for downstream classification tasks. To demonstrate the value of DeepCE, we apply it to drug repurposing of COVID-19 and generate novel lead compounds consistent with clinical evidence. DeepCE thus provides a potentially powerful framework for robust predictive modelling by utilizing noisy omics data and screening novel chemicals for the modulation of a systemic response to disease. [... keep reading](https://www.nature.com/articles/s42256-020-00285-9)
... keep reading
Gradient-Guided Dynamic Efficient Adversarial Training Edit social preview ☝
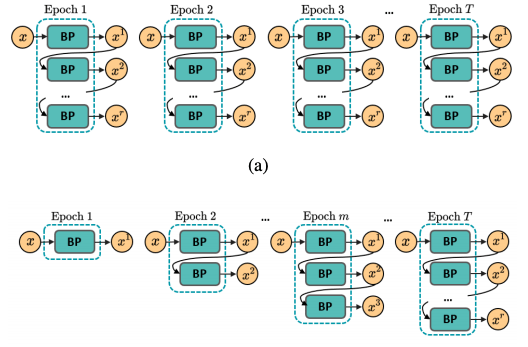
Adversarial training is arguably an effective but time-consuming way to train robust deep neural networks that can withstand strong adversarial attacks. As a response to the inefficiency, we propose the Dynamic Efficient Adversarial Training (DEAT), which gradually increases the adversarial iteration during training. Moreover, we theoretically reveal that the connection of the lower bound of Lipschitz constant of a given network and the magnitude of its partial derivative towards adversarial examples. Supported by this theoretical finding, we utilize the gradient's magnitude to quantify the effectiveness of adversarial training and determine the timing to adjust the training procedure. This magnitude based strategy is computational friendly and easy to implement. It is especially suited for DEAT and can also be transplanted into a wide range of adversarial training methods. Our post-investigation suggests that maintaining the quality of the training adversarial examples at a certain level is essential to achieve efficient adversarial training, which may shed some light on future studies. [... keep reading](https://paperswithcode.com/paper/gradient-guided-dynamic-efficient-adversarial?from=n6)
... keep reading
The Rundown
Dataset for Solving Mathematics Problems ☝

Many intellectual endeavors require mathematical problem solving, but this skill remains beyond the capabilities of computers. To measure this ability in machine learning models, we introduce MATH, a new dataset of 12,500 challenging competition mathematics problems. Each problem in MATH has a full step-by-step solution which can be used to teach models to generate answer derivations and explanations. To facilitate future research and increase accuracy on MATH, we also contribute a large auxiliary pretraining dataset which helps teach models the fundamentals of mathematics. Even though we are able to increase accuracy on MATH, our results show that accuracy remains relatively low, even with enormous Transformer models. Moreover, we find that simply increasing budgets and model parameter counts will be impractical for achieving strong mathematical reasoning if scaling trends continue. While scaling Transformers is automatically solving most other text-based tasks, scaling is not currently solving MATH. To have more traction on mathematical problem solving we will likely need new algorithmic advancements from the broader research community. [... keep reading](https://paperswithcode.com/paper/measuring-mathematical-problem-solving-with)
... keep reading