
Machine Learning Up to Date #41
Here's ML UTD #41 from the LifeWithData blog! We help you separate the signal from the noise in today's hectic front lines of software engineering and machine learning.
LifeWithData strives to deliver curated machine learning & software engineering updates that point the reader to key developments without superfluous details. This enables frequent, concise updates across the industry without information overload.
Application
Theory
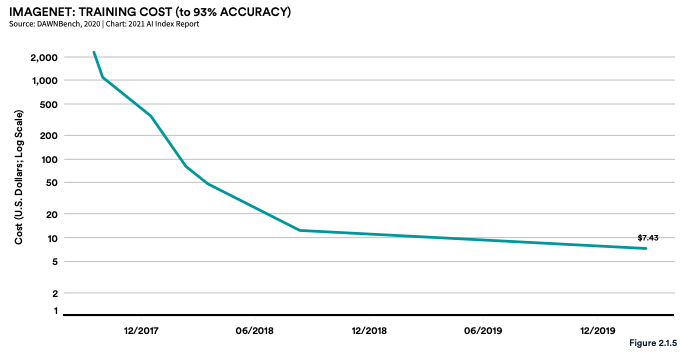
Announcing the 2021 AI Index Report ☝
This year we significantly expanded the amount of data available in the report, worked with a broader set of external organizations to calibrate our data, and deepened our connections with Stanford HAI. The 2021 report also shows the effects of COVID-19 on AI development from multiple perspectives. The Technical Performance chapter discusses how an AI startup used machine-learning-based techniques to accelerate COVID-related drug discovery during the pandemic, and our Economy chapter suggests that AI hiring and private investment were not significantly adversely influenced by the pandemic, as both grew during 2020. If anything, COVID-19 may have led to a higher number of people participating in AI research conferences, as the pandemic forced conferences to shift to virtual formats, which in turn led to significant spikes in attendance. [... keep reading](https://hai.stanford.edu/research/ai-index-2021)
... keep reading
The Rundown
Reverse ETL — A Primer ☝
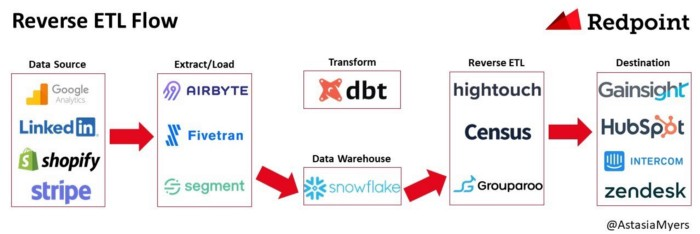
Data infrastructure has gone through an incredible evolution over the past three years. We have moved from Extract, Transform, Load (ETL) to ELT, where raw data is copied from the source system loaded into a data warehouse or data lake and then transformed. Now teams are adopting yet another new approach, called “reverse ETL,” the process of moving data from a data warehouse into third party systems to make data operational. The emergence of reverse ETL solutions is a useful component of the stack to get better leverage out of data. As teams rearchitect from ETL to ELT, the data warehouse becomes the single source of truth for data, including customer data that can be spread across different systems. Solutions that have enabled this new architecture include Fivetran and Airbyte for EL, DBT for T, and Snowflake and Redshift for the data warehouse. Traditionally data stored in data warehouses were used for analytical workloads and business intelligence applications like Looker and Superset. Data teams are now recognizing that this data can be further utilized for operational analytics, which “drives action by automatically delivering real-time data to the exact place it’ll be most useful, no matter where that is in your organization.” [... keep reading](https://medium.com/memory-leak/reverse-etl-a-primer-4e6694dcc7fb)
... keep reading
Launching the Facebook Map ☝

At Stamen, we specialize in cartography and data visualization, helping our clients to communicate with complex data. In particular, we’ve spent almost two decades designing and building interactive web maps using open source tools, such as our popular Watercolor map style using OpenStreetMap data. For the past year and a half, it’s been our privilege to work on one of our largest and most ambitious undertakings ever: collaborating closely with a team of Facebook engineers, designers, and data experts to roll out a global, multi-scale base map for all of Facebook’s billions of users. In late 2020, this map went live, and we’re extremely proud of the results. [... keep reading](https://hi.stamen.com/launching-the-facebook-map-8d028c4f0e0e)
... keep reading
The Rundown
Introducing Model Search: An Open Source Platform for Finding Optimal ML Models ☝
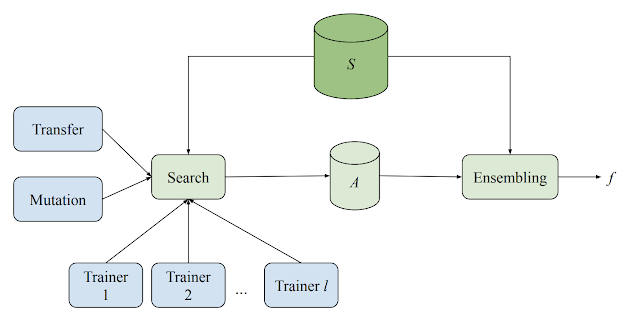
The success of a neural network (NN) often depends on how well it can generalize to various tasks. However, designing NNs that can generalize well is challenging because the research community's understanding of how a neural network generalizes is currently somewhat limited: What does the appropriate neural network look like for a given problem? How deep should it be? Which types of layers should be used? Would LSTMs be enough or would Transformer layers be better? Or maybe a combination of the two? Would ensembling or distillation boost performance? These tricky questions are made even more challenging when considering machine learning (ML) domains where there may exist better intuition and deeper understanding than others. [...] To overcome these shortcomings and to extend access to AutoML solutions to the broader research community, we are excited to announce the open source release of Model Search, a platform that helps researchers develop the best ML models, efficiently and automatically. Instead of focusing on a specific domain, Model Search is domain agnostic, flexible and is capable of finding the appropriate architecture that best fits a given dataset and problem, while minimizing coding time, effort and compute resources. It is built on Tensorflow, and can run either on a single machine or in a distributed setting. [... keep reading](https://ai.googleblog.com/2021/02/introducing-model-search-open-source.html)
... keep reading
The Rundown
Towards Causal Representation Learning ☝
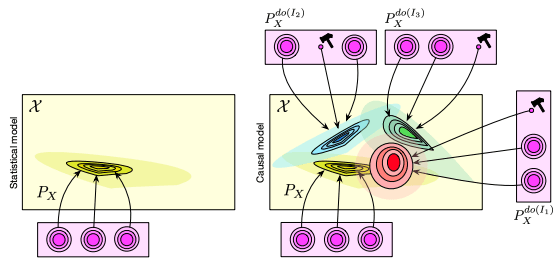
The two fields of machine learning and graphical causality arose and developed separately. However, there is now cross-pollination and increasing interest in both fields to benefit from the advances of the other. In the present paper, we review fundamental concepts of causal inference and relate them to crucial open problems of machine learning, including transfer and generalization, thereby assaying how causality can contribute to modern machine learning research. This also applies in the opposite direction: we note that most work in causality starts from the premise that the causal variables are given. A central problem for AI and causality is, thus, causal representation learning, the discovery of high-level causal variables from low-level observations. Finally, we delineate some implications of causality for machine learning and propose key research areas at the intersection of both communities. [... keep reading](https://arxiv.org/abs/2102.11107)
... keep reading
The Rundown
We’ll never have true AI without first understanding the brain ☝

The search for AI has always been about trying to build machines that think—at least in some sense. But the question of how alike artificial and biological intelligence should be has divided opinion for decades. Early efforts to build AI involved decision-making processes and information storage systems that were loosely inspired by the way humans seemed to think. And today’s deep neural networks are loosely inspired by the way interconnected neurons fire in the brain. But loose inspiration is typically as far as it goes. Most people in AI don’t care too much about the details, says Jeff Hawkins, a neuroscientist and tech entrepreneur. He wants to change that. Hawkins has straddled the two worlds of neuroscience and AI for nearly 40 years. In 1986, after a few years as a software engineer at Intel, he turned up at the University of California, Berkeley, to start a PhD in neuroscience, hoping to figure out how intelligence worked. But his ambition hit a wall when he was told there was nobody there to help him with such a big-picture project. Frustrated, he swapped Berkeley for Silicon Valley and in 1992 founded Palm Computing, which developed the PalmPilot—a precursor to today’s smartphones. [... keep reading](https://www.technologyreview.com/2021/03/03/1020247/artificial-intelligence-brain-neuroscience-jeff-hawkins/)
... keep reading
The Rundown