
Machine Learning Up to Date #32

Here's ML UTD #32 from the LifeWithData blog! We help you separate the signal from the noise in today's hectic front lines of software engineering and machine learning.
LifeWithData strives to deliver curated machine learning & software engineering updates that point the reader to key developments without superfluous details. This enables frequent, concise updates across the industry without information overload.
Application
- Production Machine Learning Monitoring: Outliers, Drift, Explainers & Statistical Performance
- MLCommons Launches and Unites 50+ Global Technology and Academic Leaders
- Introducing OpenLineage
Theory
Production Machine Learning Monitoring: Outliers, Drift, Explainers & Statistical Performance ☝
In this article we present an end-to-end example showcasing best practices, principles, patterns and techniques around monitoring of machine learning models in production. We will show how to adapt standard microservice monitoring techniques towards deployed machine learning models, as well as more advanced paradigms including concept drift, outlier detection and AI explainability. We will train an image classification machine learning model from scratch, deploy it as a microservice in Kubernetes, and introduce a broad range of advanced monitoring components. The monitoring components will include outlier detectors, drift detectors, AI explainers and metrics servers — we will cover the underlying architectural patterns used for each, which are developed with scale in mind, and designed to work efficiently across hundreds or thousands of heterogeneous machine learning models.
... keep reading
MLCommons Launches and Unites 50+ Global Technology and Academic Leaders ☝

Today, MLCommons, an open engineering consortium, launches its industry-academic partnership to accelerate machine learning innovation and broaden access to this critical technology for the public good. The non-profit organization initially formed as MLPerf, now boasts a founding board that includes representatives from Alibaba, Facebook AI, Google, Intel, and NVIDIA, as well as Professor Vijay Janapa Reddi of Harvard University; and a broad range of more than 50 founding members. The founding membership includes over 15 startups and small companies that focus on semiconductors, systems, and software from across the globe, as well as researchers from universities such as U.C. Berkeley, Stanford, and the University of Toronto. MLCommons will advance development of, and access to, the latest AI and Machine Learning datasets and models, best practices, benchmarks and metrics. An intent is to enable access to machine learning solutions such as computer vision, natural language processing, and speech recognition by as many people, as fast as possible.
... keep reading
The Rundown
Introducing OpenLineage ☝

For anyone watching the space, the acceleration of the data revolution over the last few years has been very exciting. What started as experimental deployments of “big data” projects back in the early days of Hadoop has now morphed into full production, mission-critical deployments of a whole ecosystem of new data tools – not just in leading edge tech companies but also, increasingly, across every industry. However, as data technologies conquer the world, the stakes are getting increasingly higher. In particular, it is becoming of the utmost importance that data be always available when needed, up-to-date, and correct. In other words, data needs to be trusted to power mission-critical activities. Unfortunately, the growing importance of data technologies is also accompanied by a corresponding increase in overall complexity [...] Talking with practitioners who operate these data ecosystems on a daily basis, there is an obvious tension between the growing importance of data technologies, on the one hand, and the tools available to manage them as the mission-critical systems they are becoming, on the other hand – resulting in many inefficiencies, the inability to provide strong guarantees, and thus a lack of trust in the data being used.
... keep reading
Evaluating Agents without Rewards ☝

Reinforcement learning has enabled agents to solve challenging tasks in unknown environments. However, manually crafting reward functions can be time consuming, expensive, and error prone to human error. Competing objectives have been proposed for agents to learn without external supervision, but it has been unclear how well they reflect task rewards or human behavior. To accelerate the development of intrinsic objectives, we retrospectively compute potential objectives on pre-collected datasets of agent behavior, rather than optimizing them online, and compare them by analyzing their correlations. We study input entropy, information gain, and empowerment across seven agents, three Atari games, and the 3D game Minecraft. We find that all three intrinsic objectives correlate more strongly with a human behavior similarity metric than with task reward. Moreover, input entropy and information gain correlate more strongly with human similarity than task reward does, suggesting the use of intrinsic objectives for designing agents that behave similarly to human players.
... keep reading
The Rundown
Entity Linking in 100 Languages ☝
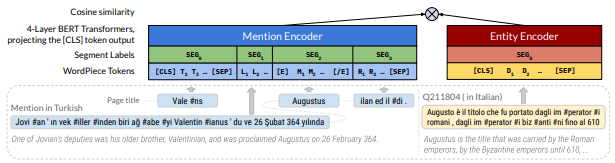
We propose a new formulation for multilingual entity linking, where language-specific mentions resolve to a language-agnostic Knowledge Base. We train a dual encoder in this new setting, building on prior work with improved feature representation, negative mining, and an auxiliary entity-pairing task, to obtain a single entity retrieval model that covers 100+ languages and 20 million entities. The model outperforms state-of-the-art results from a far more limited cross-lingual linking task. Rare entities and low-resource languages pose challenges at this large-scale, so we advocate for an increased focus on zero- and few-shot evaluation. To this end, we provide Mewsli-9, a large new multilingual dataset (http://goo.gle/mewsli-dataset) matched to our setting, and show how frequency-based analysis provided key insights for our model and training enhancements.
... keep reading
The Rundown
Google Releases its Objectron Dataset ☝

The Objectron dataset is a collection of short, object-centric video clips, which are accompanied by AR session metadata that includes camera poses, sparse point-clouds and characterization of the planar surfaces in the surrounding environment. In each video, the camera moves around the object, capturing it from different angles. The data also contain manually annotated 3D bounding boxes for each object, which describe the object’s position, orientation, and dimensions. The dataset consists of 15K annotated video clips supplemented with over 4M annotated images in the following categories: bikes, books, bottles, cameras, cereal boxes, chairs, cups, laptops, and shoes. In addition, to ensure geo-diversity, our dataset is collected from 10 countries across five continents. Along with the dataset, we are also sharing a 3D object detection solution for four categories of objects — shoes, chairs, mugs, and cameras. These models are trained using this dataset, and are released in MediaPipe, Google's open source framework for cross-platform customizable ML solutions for live and streaming media.
... keep reading