
Machine Learning Up to Date #31

Here's ML UTD #31 from the LifeWithData blog! We help you separate the signal from the noise in today's hectic front lines of software engineering and machine learning.
LifeWithData strives to deliver curated machine learning & software engineering updates that point the reader to key developments without superfluous details. This enables frequent, concise updates across the industry without information overload.
Application
- No Code Workflow Orchestrator for Building Batch & Streaming Pipelines at Scale
- 18 Machine Learning Best Practices
- Chip Huyen: MLOps Tooling Landscape v2
Theory
No Code Workflow Orchestrator for Building Batch & Streaming Pipelines at Scale ☝
At Uber, several petabytes of data move across and within various platforms every day. We power this data movement by a strong backbone of data pipelines. Whether it’s ingesting the data from millions of Uber trips or transforming the ingested data for analytical and machine learning models, it all runs through these pipelines. To put it in perspective, Uber’s data platform runs upwards of 15,000 data pipelines! But over time, the existing Python framework-based methods started showing a productivity tax on pipeline creators. The growing population of data-analysts and city-operations users inside Uber depended on a handful of data engineers to create their pipelines. What could be a few hours work often turned into a few days or weeks. In addition to that, the demand for real-time data and insights also grew quickly within Uber. But with a completely different technology stack and the complexities of building a real-time pipeline, we could not adopt real-time insight as quickly as we wanted. And getting the code right was even trickier. The need for a simpler, unified, and intuitive user experience for building data workflows was the main impetus behind uWorc, Unified Workflow Orchestrator.
... keep reading
18 Machine Learning Best Practices ☝

Machine Learning and Deep Learning (AI, in general) are no longer just buzzwords. They became an integral part of our businesses and startups. This affects software development too, in fact, it goes even further. We can’t observe machine learning components just as another part of the ecosystem, because they are part of the system that makes decisions. These components also are shifting our focus to data, which brings a different mindset when it comes to the infrastructure. Because of all these things building machine learning-based applications is not an easy task. There are several areas where data scientists, software developers and DevOps engineers need to work together in order to make a high-quality product.
... keep reading
The Rundown
Chip Huyen: MLOps Tooling Landscape v2 ☝

Last June, I published the post What I learned from looking at 200 machine learning tools. The post got some attention and I got a lot of messages from people telling me about new tools. I updated the old list to now include 284 tools. I’ll keep on updating the list as I find out about new tools. Any lead would be much appreciated! While looking for these MLOps tools, I discovered some interesting points about the MLOps landscape: 1\. Increasing focus on deployment 2\. The Bay Area is still the epicenter of machine learning, but not the only hub 3\. MLOps infrastructure in the US and China are diverging 4\. More interests in machine leanring production from academia
... keep reading
The Rundown
How to Talk When a Machine is Listening: Corporate Disclosure in the Age of AI ☝

This paper analyzes how corporate disclosure has been reshaped by machine processors, employed by algorithmic traders, robot investment advisors, and quantitative analysts. Our findings indicate that increasing machine and AI readership, proxied by machine downloads, motivates firms to prepare filings that are more friendly to machine parsing and processing. Moreover, firms with high expected machine downloads manage textual sentiment and audio emotion in ways catered to machine and AI readers, such as by differentially avoiding words that are perceived as negative by computational algorithms as compared to those by human readers, and by exhibiting speech emotion favored by machine learning software processors. The publication of Loughran and McDonald (2011) is instrumental in attributing the change in the measured sentiment to machine and AI readership. While existing research has explored how investors and researchers apply machine learning and computational tools to quantify qualitative information from disclosure and news, this study is the first to identify and analyze the feedback effect on corporate disclosure decisions, i.e., how companies adjust the way they talk knowing that machines are listening.
... keep reading
The Rundown
A Gentle Introduction to Deep Learning for Graphs ☝
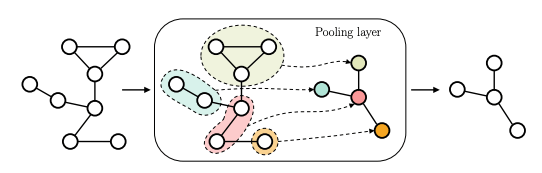
The adaptive processing of graph data is a long-standing research topic which has been lately consolidated as a theme of major interest in the deep learning community. The snap increase in the amount and breadth of related research has come at the price of little systematization of knowledge and attention to earlier literature. This work is designed as a tutorial introduction to the field of deep learning for graphs. It favours a consistent and progressive introduction of the main concepts and architectural aspects over an exposition of the most recent literature, for which the reader is referred to available surveys. The paper takes a top-down view to the problem, introducing a generalized formulation of graph representation learning based on a local and iterative approach to structured information processing. It introduces the basic building blocks that can be combined to design novel and effective neural models for graphs. The methodological exposition is complemented by a discussion of interesting research challenges and applications in the field.
... keep reading
The Rundown
Learning to Fix Programs from Error Messages ☝

When writing programs, a lot of time is spent debugging or fixing source code errors, both for beginners (imagine the intro programming classes you took) as well as for professional developers (for example, [this case study](https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/42184.pdf) from Google ). Automating program repair could dramatically enhance the productivity of both programming and learning programming. In our recent work published at ICML 2020, we study how to use machine learning to repair programs automatically.
... keep reading