
Machine Learning Up to Date #26

Here's ML UTD #26 from the LifeWithData blog! We help you separate the signal from the noise in today's hectic front lines of software engineering and machine learning.
LifeWithData strives to deliver curated machine learning & software engineering updates that point the reader to key developments without superfluous details. This enables frequent, concise updates across the industry without information overload.
Application
- Translate Between 100 Languages Without Relying on English Data
- Building Netflix’s Distributed Tracing Infrastructure
- Tensorflow Simple Audio Recognition: Recognizing keywords
Theory
Translate Between 100 Languages Without Relying on English Data ☝
Breaking language barriers through machine translation (MT) is one of the most important ways to bring people together, provide authoritative information on COVID, and keep them safe from harmful content. Today, we power an average of 20 billion translations every day on Facebook News Feed, thanks to our recent developments in low-resource machine translation and recent advances for evaluating translation quality. [...] In a culmination of many years of MT research at Facebook, we’re excited to announce a major milestone: the first single massive MMT model that can directly translate 100x100 languages in any direction without relying on only English-centric data. Our single multilingual model performs as well as traditional bilingual models and achieved a 10 BLEU point improvement over English-centric multilingual models.
... keep reading
The Rundown
Building Netflix’s Distributed Tracing Infrastructure ☝

"@Netflixhelps(https://twitter.com/Netflixhelps) Why doesn’t Tiger King play on my phone?"" — a Netflix member via Twitter. This is an example of a question our on-call engineers need to answer to help resolve a member issue — which is difficult when troubleshooting distributed systems. Investigating a video streaming failure consists of inspecting all aspects of a member account. In our previous [blog post](https://netflixtechblog.com/edgar-solving-mysteries-faster-with-observability-e1a76302c71f) we introduced Edgar, our troubleshooting tool for streaming sessions. Now let’s look at how we designed the tracing infrastructure that powers Edgar.
... keep reading
The Rundown
Tensorflow Simple Audio Recognition: Recognizing keywords ☝

... keep reading
2020’s Top AI & Machine Learning Research Papers ☝

Despite the challenges of 2020, the AI research community produced a number of meaningful technical breakthroughs. GPT-3 by OpenAI may be the most famous, but there are definitely many other research papers worth your attention. For example, teams from Google introduced a revolutionary chatbot, Meena, and EfficientDet object detectors in image recognition. Researchers from Yale introduced a novel AdaBelief optimizer that combines many benefits of existing optimization methods. OpenAI researchers demonstrated how deep reinforcement learning techniques can achieve superhuman performance in Dota 2. To help you catch up on essential reading, we’ve summarized 10 important machine learning research papers from 2020. These papers will give you a broad overview of AI research advancements this year. Of course, there are many more breakthrough papers worth reading as well.
... keep reading
The Rundown
Mitigating Unfair Bias in ML Models with the MinDiff Framework'' ☝
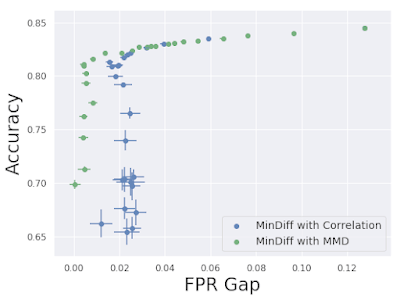
The responsible research and development of machine learning (ML) can play a pivotal role in helping to solve a wide variety of societal challenges. At Google, our research reflects our [AI Principles](https://www.blog.google/technology/ai/ai-principles/), from [helping to protect patients from medication errors](https://ai.googleblog.com/2020/04/a-step-towards-protecting-patients-from.html) and improving [flood forecasting models](https://ai.googleblog.com/2020/09/the-technology-behind-our-recent.html), to presenting methods that tackle unfair bias in products, such as [Google Translate](https://ai.googleblog.com/2020/04/a-scalable-approach-to-reducing-gender.html), and [providing resources](https://ai.googleblog.com/2020/10/measuring-gendered-correlations-in-pre.html) for other researchers to do the same. One broad category for applying ML responsibly is the task of [classification](https://en.wikipedia.org/wiki/Statistical_classification) — systems that sort data into labeled categories. At Google, such models are used throughout our products to enforce policies, ranging from the detection of hate speech to age-appropriate content filtering. While these classifiers serve vital functions, it is also essential that they are built in ways that minimize unfair biases for users. Today, we are announcing the release of [MinDiff](https://arxiv.org/pdf/1910.11779.pdf), a new regularization technique available in the [TF Model Remediation library](https://tensorflow.org/responsible_ai/model_remediation/) for effectively and efficiently mitigating unfair biases when training ML models. In this post, we discuss the research behind this technique and explain how it addresses the practical constraints and requirements we’ve observed when incorporating it in Google’s products.
... keep reading
Improving On-Device Speech Recognition with VoiceFilter-Lite ☝
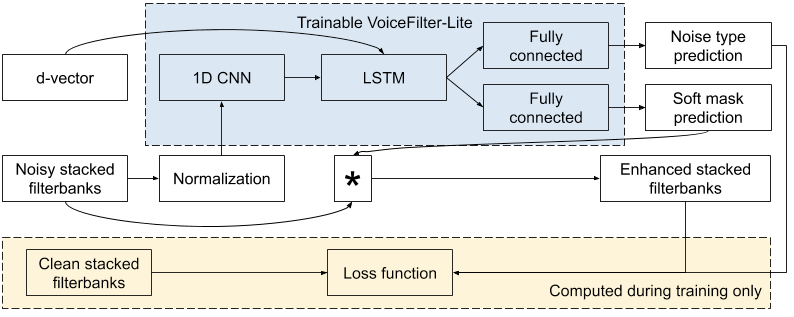
Voice assistive technologies, which enable users to employ voice commands to interact with their devices, rely on accurate [speech recognition](https://en.wikipedia.org/wiki/Speech_recognition) to ensure responsiveness to a specific user. But in many real-world use cases, the input to such technologies often consists of overlapping speech, which poses great challenges to many speech recognition algorithms. In 2018, we published a [VoiceFilter system](https://arxiv.org/abs/1810.04826), which leverages Google’s [Voice Match](https://blog.google/products/assistant/tomato-tomahto-google-home-now-supports-multiple-users/) to personalize interaction with assistive technology by allowing people to [enroll their voices](https://www.blog.google/products/assistant/more-ways-fine-tune-google-assistant-you/). While the VoiceFilter approach is highly successful, achieving a better [source to distortion ratio](https://ieeexplore.ieee.org/abstract/document/1643671) (SDR) than conventional approaches, efficient on-device streaming speech recognition requires addressing restrictions such as model size, CPU and memory limitations, as well as battery usage considerations and latency minimization. In “[VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition](https://arxiv.org/abs/2009.04323)”, we present an update to [VoiceFilter](https://arxiv.org/abs/1810.04826) for on-device use that can significantly improve speech recognition in overlapping speech by leveraging the [enrolled voice](https://www.blog.google/products/assistant/more-ways-fine-tune-google-assistant-you/) of a selected speaker. Importantly, this model can be easily integrated with existing on-device speech recognition applications, allowing the user to access voice assistive features under extremely noisy conditions even if an internet connection is unavailable. Our experiments show that a 2.2MB VoiceFilter-Lite model provides a 25.1% improvement to the [word error rate](https://en.wikipedia.org/wiki/Word_error_rate) (WER) on overlapping speech.
... keep reading
The Rundown