
Machine Learning Up to Date #22

Here's ML UTD #22 from the LifeWithData blog! We help you separate the signal from the noise in today's hectic front lines of software engineering and machine learning.
LifeWithData strives to deliver curated machine learning & software engineering updates that point the reader to key developments without superfluous details. This enables frequent, concise updates across the industry without information overload.
Application
- Understand TensorFlow by mimicking its API from scratch
- Nemo: Data Discovery at Facebook
- Emerging Architectures for Modern Data Infrastructure
Theory
Understand TensorFlow by mimicking its API from scratch ☝
TensorFlow is a very powerful and open source library for implementing and deploying large-scale machine learning models. This makes it perfect for research and production. Over the years it has become one of the most popular libraries for deep learning. The goal of this post is to build an intuition and understanding for how deep learning libraries work under the hood, specifically TensorFlow. To achieve this goal, we will mimic its API and implement its core building blocks from scratch. This has the neat little side effect that, by the end of this post, you will be able to use TensorFlow with confidence, because you’ll have a deep conceptual understanding of the inner workings. You will also gain further understanding of things like variables, tensors, sessions or operations.
... keep reading
The Rundown
Nemo: Data Discovery at Facebook ☝

Large-scale companies serve millions or even billions of people who depend on the services these companies provide for their everyday needs. To keep these services running and delivering meaningful experiences, the teams behind them need to find the most relevant and accurate information quickly so that they can make informed decisions and take action. Finding the right information can be hard for several reasons. The problem might be discovery — the relevant table might have an obscure or nondescript name, or different teams might have constructed overlapping data sets. Or, the problem could be one of confidence — the dashboard someone is looking at might have been superseded by another source six months ago. Many companies, such as [Airbnb](https://medium.com/airbnb-engineering/democratizing-data-at-airbnb-852d76c51770), [Lyft](https://eng.lyft.com/amundsen-lyfts-data-discovery-metadata-engine-62d27254fbb9), [Netflix](https://netflixtechblog.com/metacat-making-big-data-discoverable-and-meaningful-at-netflix-56fb36a53520), and [Uber,](https://eng.uber.com/databook/) have built their own custom solutions for this challenge. For us, it was important to make the data discovery process simple and fast. Funneling everything through data experts to locate the necessary data each time we need to make a decision was not scalable. So we built Nemo, an internal data discovery engine. Nemo allows engineers to quickly discover the information they need, with high confidence in the accuracy of the results.
... keep reading
The Rundown
Emerging Architectures for Modern Data Infrastructure ☝

As an industry, we’ve gotten exceptionally good at building large, complex software systems. We’re now starting to see the rise of massive, complex systems built around data – where the primary business value of the system comes from the analysis of data, rather than the software directly. We’re seeing quick-moving impacts of this trend across the industry, including the emergence of new roles, shifts in customer spending, and the emergence of new startups providing infrastructure and tooling around data. In fact, many of today’s fastest growing infrastructure startups build products to manage data. These systems enable data-driven decision making (_analytic_ systems) and drive data-powered products, including with machine learning (_operational_ systems). They range from the pipes that carry data, to storage solutions that house data, to SQL engines that analyze data, to dashboards that make data easy to understand – from data science and machine learning libraries, to automated data pipelines, to data catalogs, and beyond. And yet, despite all of this energy and momentum, we’ve found that there is still a tremendous amount of confusion around what technologies are on the leading end of this trend and how they are used in practice. In the last two years, we talked to hundreds of founders, corporate data leaders, and other experts – including interviewing 20+ practitioners on their current data stacks – in an attempt to codify emerging best practices and draw up a common vocabulary around data infrastructure. This post will begin to share the results of that work and showcase technologists pushing the industry forward.
... keep reading
The Rundown
mT5: Massively Multilingual Pre-trained Text-to-text ☝
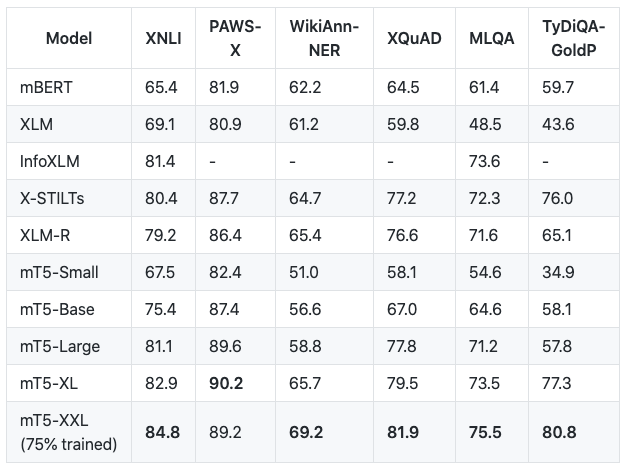
The recent "Text-to-Text Transfer Transformer" (T5) leveraged a unified text-to-text format and scale to attain state-of-the-art results on a wide variety of English-language NLP tasks. In this paper, we introduce mT5, a multilingual variant of T5 that was pre-trained on a new Common Crawl-based dataset covering 101 languages. We describe the design and modified training of mT5 and demonstrate its state-of-the-art performance on many multilingual benchmarks. All of the code and model checkpoints used in this work are publicly available.
... keep reading
The Rundown
LambdaNetworks: Modeling Long-range Interactions without Attention ☝

We present a general framework for capturing long-range interactions between an input and structured contextual information (e.g. a pixel surrounded by other pixels). Our method, called the lambda layer, captures such interactions by transforming available contexts into linear functions, termed lambdas, and applying these linear functions to each input separately. Lambda layers are versatile and may be implemented to model content and position-based interactions in global, local or masked contexts. As they bypass the need for expensive attention maps, lambda layers can routinely be applied to inputs of length in the thousands, en-abling their applications to long sequences or high-resolution images. The resulting neural network architectures, LambdaNetworks, are computationally efficient and simple to implement using direct calls to operations available in modern neural network libraries. Experiments on ImageNet classification and COCO object detection and instance segmentation demonstrate that LambdaNetworks significantly outperform their convolutional and attentional counterparts while being more computationally efficient. Finally, we introduce LambdaResNets, a family of LambdaNetworks, that considerably improve the speed-accuracy tradeoff of image classification models. LambdaResNets reach state-of-the-art accuracies on ImageNet while being ∼4.5x faster than the popular EfficientNets on modern machine learning accelerators.
... keep reading
The Rundown
Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition ☝
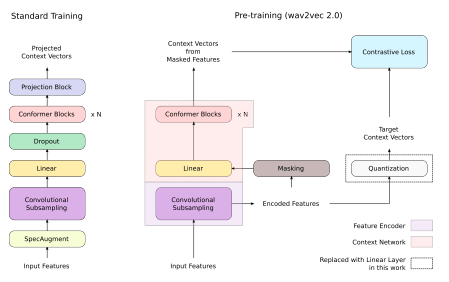
We employ a combination of recent developments in semi-supervised learning for automatic speech recognition to obtain state-of-the-art results on LibriSpeech utilizing the unlabeled audio of the Libri-Light dataset. More precisely, we carry out noisy student training with SpecAugment using giant Conformer models pre-trained using wav2vec 2.0 pre-training. By doing so, we are able to achieve word-error-rates (WERs) 1.4%/2.6% on the LibriSpeech test/test-other sets against the current state-of-the-art WERs 1.7%/3.3%.
... keep reading
The Rundown