
Machine Learning Up to Date #20

Here's ML UTD #20 from the LifeWithData blog! We help you separate the signal from the noise in today's hectic front lines of software engineering and machine learning.
LifeWithData strives to deliver curated machine learning & software engineering updates that point the reader to key developments without superfluous details. This enables frequent, concise updates across the industry without information overload.
Application
- Facebook’s BLINK: a Wikipedia-based Entity-linking Python Library
- Awful AI Tracks Misuse of AI in Society
- Lean Data Science
Theory
Facebook’s BLINK: a Wikipedia-based Entity-linking Python Library ☝
This paper introduces a conceptually simple, scalable, and highly effective BERT-based entity linking model, along with an extensive evaluation of its accuracy-speed trade-off. We present a two-stage zero-shot linking algorithm, where each entity is defined only by a short textual description. The first stage does retrieval in a dense space defined by a bi-encoder that independently embeds the mention context and the entity descriptions. Each candidate is then re-ranked with a crossencoder, that concatenates the mention and entity text. Experiments demonstrate that this approach is state of the art on recent zeroshot benchmarks (6 point absolute gains) and also on more established non-zero-shot evaluations (e.g. TACKBP-2010), despite its relative simplicity (e.g. no explicit entity embeddings or manually engineered mention tables). We also show that bi-encoder linking is very fast with nearest neighbour search (e.g. linking with 5.9 million candidates in 2 milliseconds), and that much of the accuracy gain from the more expensive crossencoder can be transferred to the bi-encoder via knowledge distillation.
... keep reading
Awful AI Tracks Misuse of AI in Society ☝

Awful AI is a curated list to track _current_ scary usages of AI - hoping to raise awareness to its misuses in society Artificial intelligence in its current state is [unfair](https://github.com/rockita/criticalML), [easily susceptible to attacks](http://www.cleverhans.io/security/privacy/ml/2016/12/16/breaking-things-is-easy.html) and [notoriously difficult to control](https://docs.google.com/spreadsheets/u/1/d/e/2PACX-1vRPiprOaC3HsCf5Tuum8bRfzYUiKLRqJmbOoC-32JorNdfyTiRRsR7Ea5eWtvsWzuxo8bjOxCG84dAg/pubhtml). Often, AI systems and predictions [amplify existing systematic biases](https://twitter.com/kaiwei_chang/status/1274845029933084673) even when the data is balanced. Nevertheless, more and more concerning the uses of AI technology are appearing in the wild. This list aims to track _all of them_. We hope that _Awful AI_ can be a platform to spur discussion for the development of possible preventive technology (to fight back!).
... keep reading
The Rundown
Lean Data Science ☝

It’s becoming more and more clearly recognized that the promises of the machine-learning revolution, at least for your average non-big-tech company, are not delivering the value that many had hoped for. That is, many executives are looking at the fleet of data scientists they hired and not seeing the return on investment they were hoping for. [...] Beyond the fact that a lot of snake-oil salespeople over-sold the capabilities of AI in general, I believe that we data scientists, as a profession, have focused too much on algorithms and methods, and not enough on how to _deliver business value_. We can deliver more value as data scientists by adopting a lean data science methodology that emphasizes experimentation and iteration at the product level instead of focusing on measures of model performance not directly tied to business value.
... keep reading
The Rundown
CrowS-Pairs: a Dataset for Measuring Social Biases in Masked Language Models ☝

Pretrained language models, especially masked language models (MLMs) have seen success across many NLP tasks. However, there is ample evidence that they use the cultural biases that are undoubtedly present in the corpora they are trained on, implicitly creating harm with biased representations. To measure some forms of social bias in language models against protected demographic groups in the US, we introduce the Crowdsourced Stereotype Pairs benchmark (CrowS-Pairs). CrowS-Pairs has 1508 examples that cover stereotypes dealing with nine types of bias, like race, religion, and age. In CrowS-Pairs a model is presented with two sentences: one that is more stereotyping and another that is less stereotyping. The data focuses on stereotypes about historically disadvantaged groups and contrasts them with advantaged groups. We find that all three of the widely-used MLMs we evaluate substantially favor sentences that express stereotypes in every category in CrowS-Pairs. As work on building less biased models advances, this dataset can be used as a benchmark to evaluate progress.
... keep reading
Hyperbolic Hierarchical Clustering in PyTorch ☝
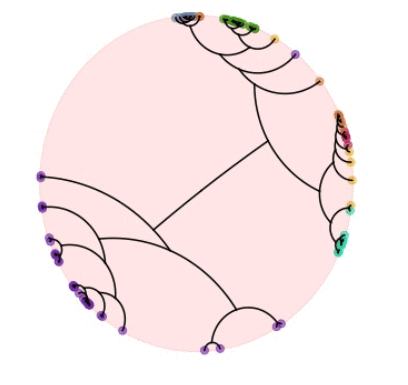
Similarity-based Hierarchical Clustering (HC) is a classical unsupervised machine learning algorithm that has traditionally been solved with heuristic algorithms like Average-Linkage. Recently, Dasgupta reframed HC as a discrete optimization problem by introducing a global cost function measuring the quality of a given tree. In this work, we provide the first continuous relaxation of Dasgupta's discrete optimization problem with provable quality guarantees. The key idea of our method, HypHC, is showing a direct correspondence from discrete trees to continuous representations (via the hyperbolic embeddings of their leaf nodes) and back (via a decoding algorithm that maps leaf embeddings to a dendrogram), allowing us to search the space of discrete binary trees with continuous optimization. Building on analogies between trees and hyperbolic space, we derive a continuous analogue for the notion of lowest common ancestor, which leads to a continuous relaxation of Dasgupta's discrete objective. We can show that after decoding, the global minimizer of our continuous relaxation yields a discrete tree with a (1 + epsilon)-factor approximation for Dasgupta's optimal tree, where epsilon can be made arbitrarily small and controls optimization challenges. We experimentally evaluate HypHC on a variety of HC benchmarks and find that even approximate solutions found with gradient descent have superior clustering quality than agglomerative heuristics or other gradient based algorithms. Finally, we highlight the flexibility of HypHC using end-to-end training in a downstream classification task.
... keep reading
The Rundown
Stanford’s Machine Learning Systems Seminar Series ☝

{kind=link}
{kind=link}
Machine learning is driving exciting changes and progress in computing. What does the ubiquity of machine learning mean for how people build and deploy systems and applications? What challenges does industry face when deploying machine learning systems in the real world, and how can academia rise to meet those challenges? In this seminar series, we want to take a look at the frontier of machine learning systems, and how machine learning changes the modern programming stack. Our goal is to help curate a curriculum of awesome work in ML systems to help drive research focus to interesting questions.
... keep reading
The Rundown