
Machine Learning Up to Date #19
Here's ML UTD #19 from the LifeWithData blog! We help you separate the signal from the noise in today's hectic front lines of software engineering and machine learning.
LifeWithData strives to deliver curated machine learning & software engineering updates that point the reader to key developments without superfluous details. This enables frequent, concise updates across the industry without information overload.
Application
- TensorSensor: Clarifying Exceptions and Visualizing Tensor Operations in Deep Learning Code
- Real Time Machine Learning at Scale using SpaCy, Kafka & Seldon Core
- Rise of the Canonical Stack in Machine Learning
Theory
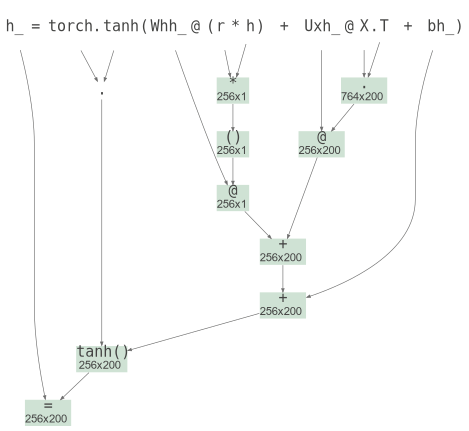
TensorSensor: Clarifying Exceptions and Visualizing Tensor Operations in Deep Learning Code ☝
Most people solve deep learning problems using high-level libraries such as [Keras](https://keras.io/) or [fastai](https://www.fast.ai/), which makes sense. These libraries hide a lot of implementation details that we either don't care about or can learn later. To truly understand deep learning, however, I think it's important at some point to implement your own network layers and training loops. For example, see my recent article called [Explaining RNNs without neural networks](https://explained.ai/rnn/index.html). If you're comfortable building deep learning models while leaving some of the details a bit fuzzy, then this article is not for you. In my quirky case, I care more about learning something deeply than actually applying it to something useful, so I go straight for the details. (I guess that's why I work at a university, not in industry 😀.) This article is in response to a pain point I experienced during an obsessive coding and learning burn through the fundamentals of deep learning in the isolation of Covid summer 2020.
... keep reading
The Rundown
Real Time Machine Learning at Scale using SpaCy, Kafka & Seldon Core ☝

In this post, we will cover how to train and deploy a machine learning model leveraging a scalable stream processing architecture for an automated text prediction use-case. We will be using [Sklearn](https://github.com/scikit-learn/scikit-learn) and [SpaCy](https://spacy.io/) to train an ML model from the Reddit Content Moderation dataset, and we will deploy that model using Seldon Core for real time processing of text data from Kafka real-time streams. You can also find an overview of the content in this post in video form, presented at the [NLP Summit 2020](https://www.youtube.com/watch?v=T0pPn5KTxFE).
... keep reading
The Rundown
Rise of the Canonical Stack in Machine Learning ☝
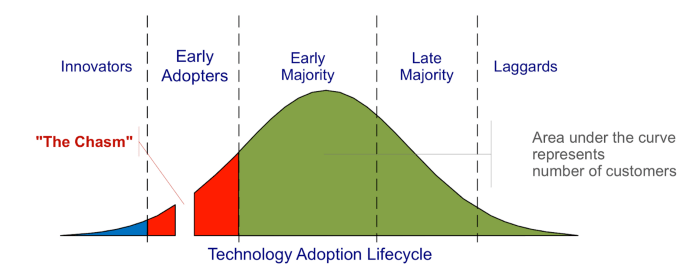
With every generation of computing comes a dominant new software or hardware stack that sweeps away the competition and catapults a fledgling technology into the mainstream. I call it the **Canonical Stack (CS)**. Think the WinTel dynasty in the 80s and 90s, with Microsoft on 95% of all PCs with “Intel inside.” Think [LAMP](https://en.citizendium.org/wiki/LAMP_(application_stack)) and [MEAN](https://en.wikipedia.org/wiki/MEAN_(solution_stack)) stack. Think Amazon’s [S3 becoming a near universal](https://www.architecting.it/blog/has-s3-become-the-de-facto-api-standard/) API for storage. Think of [Kubernetes and Docker](https://www.amazon.com/Kubernetes-Running-Dive-Future-Infrastructure-ebook/dp/B07YP1XSZ9/ref=sr_1_1?dchild=1&keywords=kubernetes&qid=1597401588&sr=8-1) for cloud orchestration. The stack emerges from the noise of tens of thousands of other solutions, as organizations look to solve the same super challenging problems. In the beginning of any complex system, the problems are legion. Stalled progress on one blocked progress on dozens of others. But as people solve one problem completely, it unlocks the door to a massive number of new solutions.
... keep reading
The Rundown
Yann LeCun’s Deep Learning Course at CDS is Now Fully Online & Accessible to All ☝

CDS is excited to announce the release of all materials for Yann LeCun’s [Deep Learning, DS-GA 1008](https://atcold.github.io/pytorch-Deep-Learning/), co-taught in Spring 2020 with Alfredo Canziani. This unique course material consists of a mix of close captioned lecture videos, detailed written overviews, and executable Jupyter Notebooks with PyTorch implementations. The course covers the latest techniques in both deep learning and representation learning, focusing on supervised/self-supervised learning, embedding methods, metric learning, convolutional and recurrent nets, with applications to computer vision, natural language understanding, and speech recognition. Course prerequisites include [DS-GA 1001 Intro to Data Science](https://github.com/briandalessandro/DataScienceCourse) OR a machine learning course.
... keep reading
The Rundown
Robustness of Bayesian Neural Networks to Gradient-Based Attacks ☝

Deep learning’s vulnerability to adversarial attacks has become a hot topic in machine learning research. While so far there has (thankfully) been few examples of true adversarial attacks impacting deployed models ‘in the wild’, the increasing reliance on ML models for practical applications means that this is an important weakness to protect against. In fact, there doesn’t even need to be an ‘adversary’ with bad intentions present for this to be something worth considering. A few innocent but unusual examples can be enough to cause catastrophic failure in a deployed model, as neural networks can be sensitive to data points which are far in distribution from their training dataset, leading to predictions which are both over-confident and wrong (see [Gal et al (2015)](https://arxiv.org/pdf/1506.02142.pdf) Fig 1. for an example). The authors of the paper discussed here note a [tragic accident](https://www.theguardian.com/technology/2016/jun/30/tesla-autopilot-death-self-driving-car-elon-musk) where a misclassification error in a object detection system contributed to the death of a car driver. Bayesian neural networks (BNNs), are a class of models which have been proposed as a way to address many shortcomings of modern neural networks, particularly in the area of safety critical systems (see for example [Deep Learning Is Not Good Enough, We Need Bayesian Deep Learning for Safe AI](https://alexgkendall.com/computer_vision/bayesian_deep_learning_for_safe_ai/)). BNNs have a couple of generally desirable properties: Producing uncertainty estimates of their predictions which can be used to aid decision makingProviding a certain amount of robustness due to the regularizing property of the prior distribution
... keep reading
The Rundown
Reinforcement Learning is Supervised Learning on Optimized Data ☝

The two most common perspectives on Reinforcement learning (RL) are **optimization** and **dynamic programming**. Methods that compute the gradients of the non-differentiable expected reward objective, such as the REINFORCE trick are commonly grouped into the optimization perspective, whereas methods that employ TD-learning or Q-learning are dynamic programming methods. While these methods have shown considerable success in recent years, these methods are still quite challenging to apply to new problems. In contrast deep supervised learning has been extremely successful and we may hence ask: _Can we use supervised learning to perform RL?_ In this blog post we discuss a mental model for RL, based on the idea that RL can be viewed as doing supervised learning on the “good data”. What makes RL challenging is that, unless you’re doing imitation learning, actually acquiring that “good data” is quite challenging. Therefore, RL might be viewed as a _joint optimization_ problem over both the policy and the data. Seen from this **supervised learning** perspective, many RL algorithms can be viewed as alternating between finding good data and doing supervised learning on that data. It turns out that finding “good data” is much easier in the multi-task setting, or settings that can be converted to a different problem for which obtaining “good data” is easy. In fact, we will discuss how techniques such as hindsight relabeling and inverse RL can be viewed as optimizing data.
... keep reading
The Rundown